The interim meeting of the Research and Analysis of Standard-Setting Processes Proposed Research Group was held on 16 May 2023. Several members of the sodestream team participated ( (Ignacio Castro, Stephen McQuistin, and Colin Perkins) and were involved in the discussion.
For more info about the discussion you can have a look at the meeting agenda, minutes, and materials.
ACL 2023 paper - Tracing Linguistic Markers of Influence in a Large Online Organisation
We have published a new main conference paper at ACL!
Intro
Social science and psycholinguistic research have shown that power and status affect how people use language in a range of domains. In our recent ACL paper, we investigate a similar question in the Internet Engineering Task Force (IETF). Our analysis, based on lexical categories (LIWC) and BERT, shows that participants’ levels of influence can be predicted from their email text, and identifies key linguistic differences (e.g., certain LIWC categories, such as WE are positively correlated with high-influence). We also identify the differences in language use for the same person before and after becoming influential.
Specifically, we explore the following research questions: RQ1: How do linguistic traits differ between more and less influential participants? RQ2: How do linguistic traits vary for participants at different levels of the organization hierarchy? RQ3: How does linguistic behaviour of participants change as they gain influence?
Methods
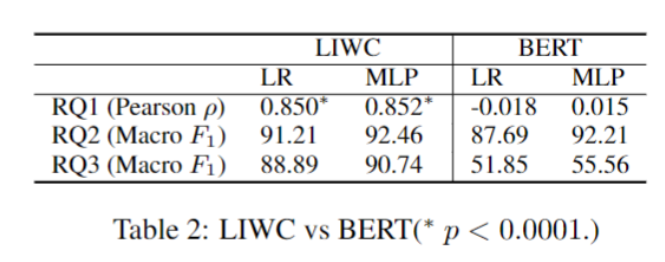
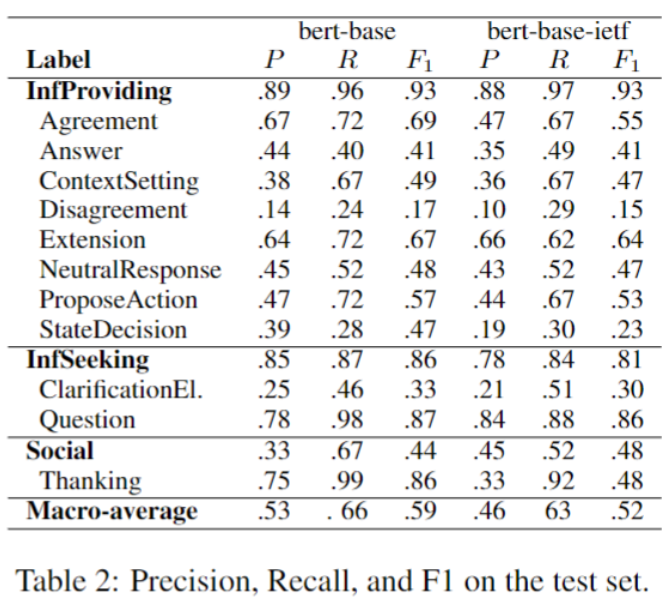
To tackle these questions we create three classification / regression problems as follows.All tasks have as input a set of LIWC features calculated on a subset of emails of a participant. The prediction tasks are as follows. RQ1: predict the influence percentile of a person, defined as their centrality score in the email communication network. RQ2: predict whether a person is a working group chair or not. RQ3: predict whether the person’s communication occurred before or after they became influential (as defined in RQ1). The significant (p < 0.05) LIWC features are given in the table below.
Results:
RQ1: The first and third person plural pronoun usage indicates that influential people tend to adopt a collaborative and community-oriented approach. Moreover, they also use more organisational language, indicated by negative correlation with less formal LIWC categories, such as netspeak and sexual.
RQ2: Working group (WG) chairs are more social and collaborative, as is shown by the we and social LIWC categories. They also use more tentative statements in discussions primarily focused on technical feedback and revisions, or suggesting alternatives
RQ3: We observe that, as they gain influence, participants tend to become more descriptive and engaged in the immediate state of issues and situations. They are also more involved in cognitive processes as compared to their previous self when they were new to IETF and had little influence.
Discussion
We further investigated the trends using separate word-level regression models for words in the LIWC categories that were prominent in the experiments. This revealed not all words within the same category have the same trend. For example, the negemo category is more prominent in influential people mostly because they use words like “problems”, even though they do this in a constructive way to provide feedback and point out limitations. We also observed some unexpected trends are related to ambiguous words which have specific meanings in technical discussions (e.g., “live” is often used in “keep connection alive” and “kill” in “kill the process/thread”, which is not typical of standard language use).
Prediction experiments:
Finally, we experimented with large pretrained language models (BERT) to see how their predictive power would compare to the LIWC features. The results, given below, show that the hand-crafted LIWC features are still somewhat better tailored to these prediction tasks
ACL 2023 findings paper - LEDA: a Large-Organization Email-Based Decision-Dialogue-Act Analysis Dataset
We have published a new paper in the Findings of the ACL!
Intro
Collaboration increasingly happens online. This is especially true for large groups working on global tasks, with collaborators all around the world. The size and distributed nature of such groups make decision-making challenging. In our new paper we propose a set of dialog acts for the study of decision-making mechanisms in such groups, and provide a new annotated dataset based on real-world data from the Internet Engineering Task Force (IETF). We also provide some interesting results of an initial exploratory data analysis
Annotation
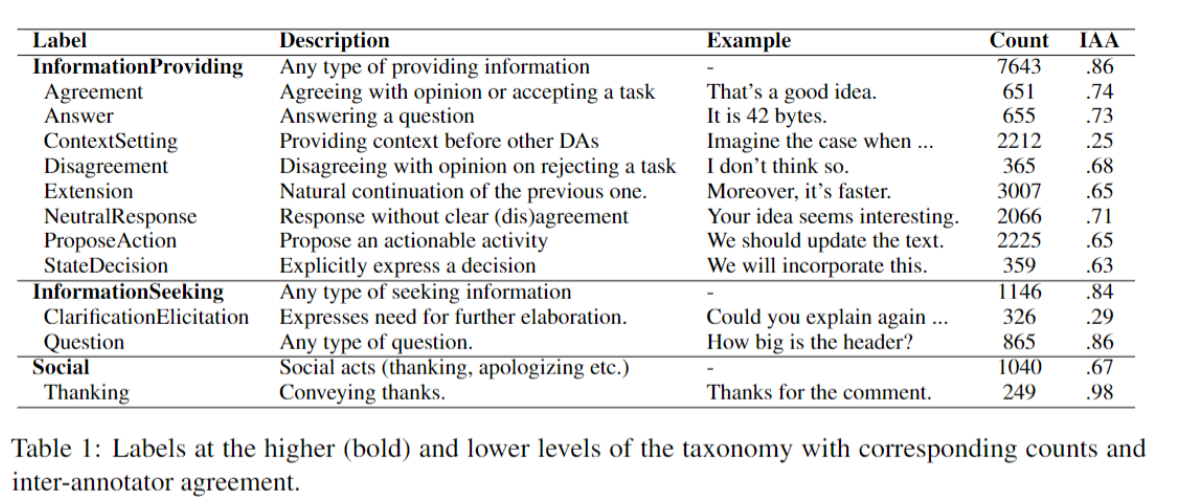
After experimenting with many variants of the label taxonomy in collaboration with annotators who were trained linguists we converged to the set of dialogue-act (DA) labels given in the table below:
For annotation, we’ve split emails into segments and had at least two annotators independently label each segment. For this purpose we used a custom tool developed specifically for this task. We allow the same instance to be labeled with an arbitrary number of labels at the same time, making the task multilabel.
Experiments
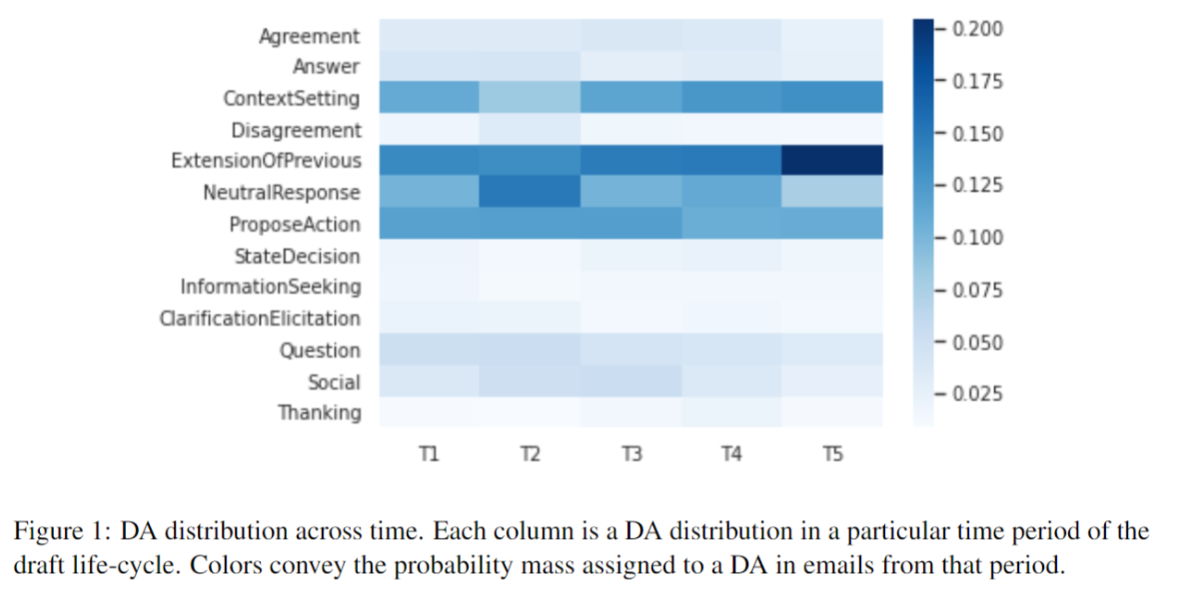
We divided the lifecycle of the draft into five periods (T1 … T5). Below we give the distribution of each dialogue act across the periods.
We found that Answer and Question are more common in the early phases, likely due to more new issues being raised and unresolved issues discussed. ContextSetting and Extension are very frequent, increasingly so towards the end phases; we conjecture this is because those phases cover more complex issues requiring more background description. The frequency of ProposeAction is stable throughout the cycle and noticeably higher than StateDecision. This may imply that participants prefer to discuss actionable options rather than explicitly deciding on a single one.
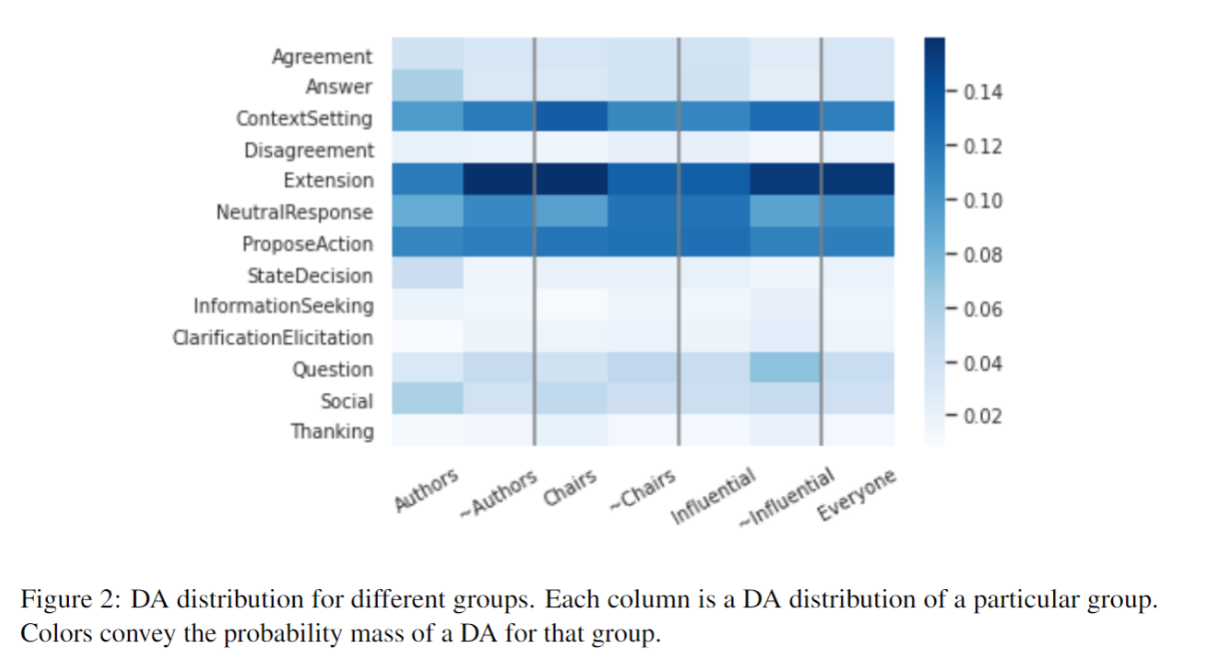
We then divided the participants in terms of their role within the organisation – draft authors, working group chairs, and influencers (participants with high centrality in the email communication network).
Authors vs. non-Authors Authors are more social, give more answers, and ask fewer questions. Also, they use fewer NeutralResponse, Extension, and ContextSetting, indicating shorter, more focused messages. These trends imply they take a more reactive role in the discussion. Finally, they make the most decisions in the discussion, as would be expected, since they are in charge of the writing process.
Influential vs. non-Influential Influential people use Answer, Agreement, and NeutralResponse more, making them generally more responsive. They use less Extension, ContextSetting and Thanking, implying a concise, focused communication style. As expected, they make more decisions and propose slightly more actions.
Chairs vs. non-Chairs Similar to influential participants, chairs use NeutralResponse more than non-Chairs. However, they use more ContextSetting and Extension, and do more Thanking. We find this is because chairs send a lot of emails initiating and managing discussions and review assignments. Such emails are often composed of many small segments and contain a lot of these labels.
Prediction model
Finally, we made a BERT based prediction model for these DAs, which can serve as a baseline for more advanced models in future work. Results are given in the table below.
IETF 116 took place in Yokohama, Japan from March 27th through March 31st 2023, with the Hackathon held on the weekend beforehand. Many sodestream project members attended (Ignacio Castro, Stephen McQuistin, Colin Perkins, and Gareth Tyson) and were involved in activities throughout the week.
Hackathon
Kicking off the week, we took part in the Hackathon in the weekend prior to the IETF meeting. We focused on two main areas during the Hackathon: first, looking at how the tools and datasets that the projects has developed and generated so far might best be shared with the wider community. This discussion ultimately concluded with the creation of a GitHub organisation for the Research and Analysis of Standard-Setting Processes Proposed Research Group, where we will be able to contribute our code.
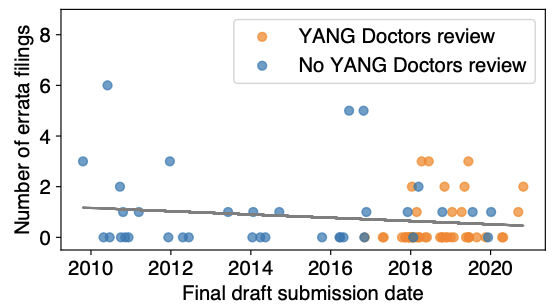
The impact of YANG Doctors on the rate of errata filings for YANG-related RFCs
In addition, we also continued ongoing work looking at errata filings for RFCs, and the impact that different interventions have on the rate of filings. Our early results indicate that, for example, review teams and directorates can reduce the volume of errata that are filed. This work was included in a paper that has recently been accepted to appear at the Network Traffic Measurement and Analysis Conference; we will share further details soon.
Hot RFC
Ignacio Castro presenting in the Hot RFC session at IETF 116 in Yokohama
Ignacio Castro advertised the Research and Analysis of Standard-Setting Processes Proposed Research Group meeting at the Hot RFC session. This group -- the formation of which had previously been discussed at IETF 115 -- has been chartered to bring together researchers, practitioners, policy makers, standards users, and standards developers to study standardisation processes. Decision making, which is the focus of the sodestream project, is a significant part of those processes, and we look forward to contributing to the group.
Research and Analysis of Standard-Setting Processes Proposed Research Group
Stephen McQuistin presenting in the Research and Analysis of Standard-Setting Processes Proposed Research Group meeting at IETF 116
The meeting itself, led by Ignacio Castro and Niels ten Oever, was well attended, both in person and remotely, and the agenda included presentations and discussion about standards-setting processes, the data that we can collect about them, and the analysis that might be useful to conduct.
Stephen McQuistin presented the project's work on a draft reviewer recommender tool. Largely developed by Mladen Karan, the tool allows users to enter the name of a draft and indicate the type of focus that the reviewers should have. The tool then produces a list of reviewer candidates, drawn from matching the topics that IETF participants discuss on the mailing lists, with the topics that are associated with the Internet Draft.
Stephen's presentation outlined the tool, and described the mechanisms behind the matching process. The feedback gained -- both during the talk, and in e-mails afterwards -- has been valuable in further developing and extending the tool.
IETF 115 was held in London from 5th November through 11th November 2022, with members of the "Streamlining Social Decision Making for Improved Internet Standards" (sodestream) project taking part in activities throughout the meeting.
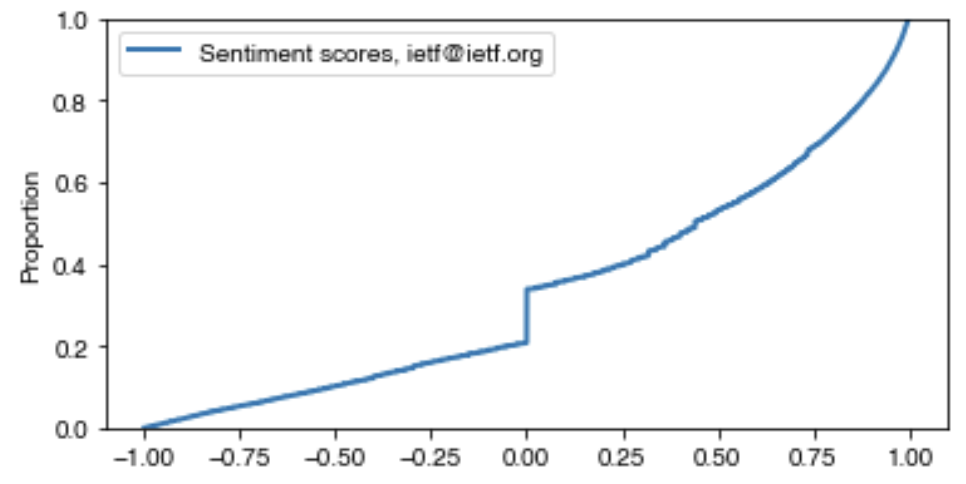
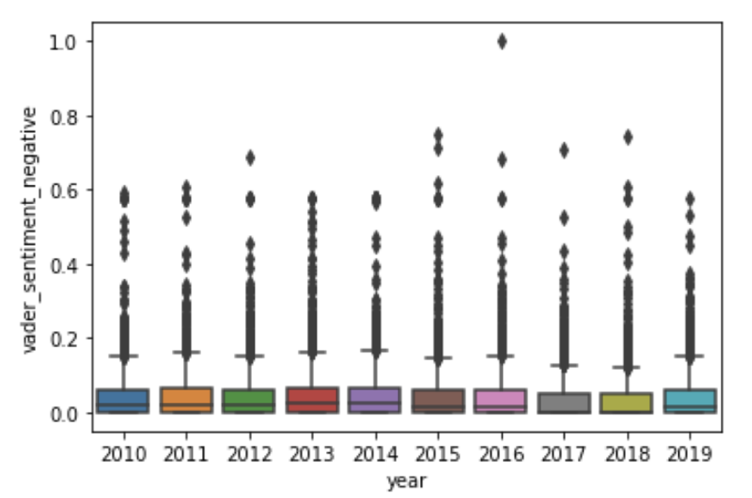
The focus of our work at the Hackathon was on analysing the sentiment of postings to the ietf@ietf.org mailing list. This mailing list provides a forum for the broad discussion of IETF-related topics. Sentiment analysis techniques could be useful in characterising the tone, and levels of toxicity, in the interactions that take place on this, and other, IETF mailing lists. With historical data, these trends can be tracked over time, providing insight into how the IETF community is evolving. The team managed to generate a dataset of sentiment scores, passing e-mail through the VADER library to understand if messages are broadly positive, negative, or neutral. In addition, they started to plot broad trends over time, and for individuals, and sketched out improvements to tooling documentation and packaging.
Distribution of VADER sentiment scores for all ietf@ietf.org postingsDistributions of sentiment scores for all ietf@ietf.org postings, within each year
There initial evidence of some interesting trends: relatively low levels of negativity, with more negativity on found on postings made on weekends and via person e-mail addresses, and relatively more positivity on Monday's. Broadly, however, the team found that sentiment analysis over technical text is difficult. For example, phrases like "dropped packets", "killed process", and "abort transmission" are neutral technical phrases that are scored negatively by the sentiment analysis library. It is essential to build up a lexicon of technical phrases to avoid misclassification.
Presentations
Ignacio Castro presenting a summary of our findings so far at IETF 115
Ignacio Castro presented a summary of our recent work to meetings of the Internet Engineering Steering Group (slides), the Working Group Chair Forum (slides), and the Measurement and Analysis of Protocols Research Group (slides, recording). These presentations highlighted our findings, including that conversations seem to be getting more complex, publishing is harder, and that the relevance of a minority of influential participants is growing. Our findings suggest that these are interconnected.
Proposed Research and Analysis of Standardisation Processes Research Group (RASP RG)
Finally, the team contributed to a meeting to discuss a proposal to form a Research and Analysis of Standardisation Processes Research Group within the IRTF. The meeting, led by Ignacio Castro and Niels ten Oever, highlighted the broad themes that relate to building an understanding of standardisation processes. These include understanding IP disclosure rules, barriers to participation, leadership dynamics, and decision making processes. The aim of the proposed group would be to improve our understanding of the development of standards-setting organisations, bringing together a community of researchers, practitioners, and standards developers and users. These themes and objectives align well with the core motivation of the sodestream project, and we look forward to contributing to the development of the group.
Impact of early engagement on longevity of IETF participation
What factors influence an Internet Engineering Task Force (IETF) participant to remain engaged with the IETF community for a long time? Are there early signs that can indicate whether a new participant will go on to stay engaged with IETF activities for a long time or are they likely to get disengaged?
In our recent work, we have attempted to find answers to these questions. Nearly 4000 participants per year were found to actively participate across various mailing lists between 2000-2004. During this period nearly 2000 new participants per year joined various mailing lists. By the beginning of the next decade (2011-), the number of active participants per year (across mailing lists) were still close to 4000. While this could reflect an entirely new generation of IETF participants across different time periods or a combination of some old participants still active along with the new participants, the reality is that a significant proportion of new people who joined over the years eventually became inactive or disengaged with the IETF community, at least on the mailing lists.
So we decided to look at the interaction behaviour of the new joiners over the years. Without giving too much away, we find out that engaging people early in their life span may be the most effective tool to keep participants engaged. We notice a clear difference in the early age interaction activities of those who go on to stay for a long time in comparison to those who leave early.
Methodology
We take over 1100 IETF mailing lists archives (all the mailing lists available at the time of download) and, for each user, determine their activity period (also referred to as ‘age’). This is the time period between their first and last email exchange. Note that we identify users with multiple accounts and create unique identifiers, resulting in more than 200,000 identifiers.
The first thing we notice is that the data is dominated by users who only send one or two emails (covering around 83% of all users). The one-time emails can often vary between spam emails, introduction/greet emails, etc. To avoid skewing the results, we therefore apply a filter to consider only users who have sent at least three messages. It is important to note that the remaining 17% of the accounts contributed towards over 90% of the total volume of emails (over 2.8 million emails).
Analysis
Question: How many years do IETF participants generally remain active, as they join over the years?
To begin with, we are curious about the age (years of remaining active) that IETF participants tend to acquire. Figure 1 shows a kernel density of final age acquired by people joining over the years. The colour density bar on the side shows increasing order of the probability where the colour intensity is high. It gives an indication that while a high number of people leave early (as the darker contours of density at the bottom suggest a higher probability for more participants leaving early), some participants go on to stay for a few more years and some participants go on to remain active for as long as they could.
Kernel Density: Age acquired by people joining each year (Figure 1)
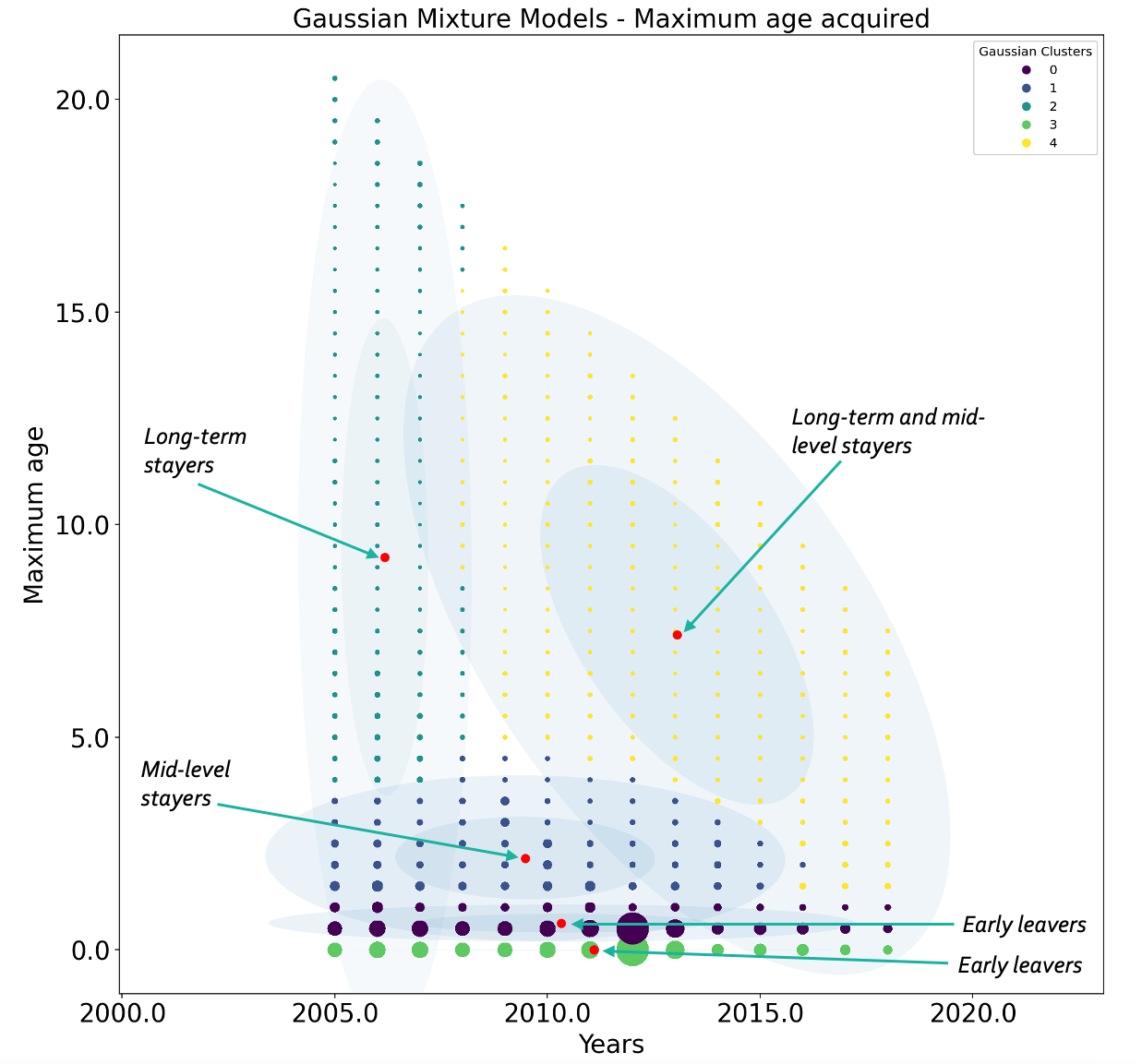
To understand more about the age categories we generated Gaussian Mixture Models (GMM) to reveal the possible clusters of age probability distribution that the participants go on to acquire. The data reflects the year in which the person exchanged email for the first time (year born), and the number of years the person remains active for (age).
We generate five Gaussian maximum age clusters, where each person belongs to a particular cluster. Each of these clusters are then manually analysed and some of the clusters are further merged as they were identified to be of similar age categories. Figure 2 shows, broadly, three categories of maximum acquired age, for users joining each year between the years 2000 and 2013 (to allow participants a time window to fully exhibit their longevity of association). The three broad categories identified are:
Early leavers: participants who go on to get inactive within 1 year of joining IETF.
Mid-level stayers: participants who go on to remain active for a period between 1 and 5 years before getting inactive.
Long-term stayers: participants who go onto remain active for 5 or more years.
This is an interesting observation since these categories are, broadly, consistent over an observed period of 13 years. Substantial proportion of people leave within a year or so throughout this time period, while some indeed go onto remain active for 5 or more years.
Participant Category
Number of participants
Early leavers
17142
Mid-level stayers
5349
Long-term stayers
4833
Number of participants across categories (Table 1)
Gaussian Mixture Models: max age acquired over the years (Figure 2)
Now that we have identified how IETF participants cluster regarding the age they go on to acquire, we explore what factors influence the length of their association.
Question: Is early age interaction activity indicative of how long a new participant goes on to remain active?
What is an interaction? - participants either respond to someone’s email on the mailing lists or their email is responded to by some participant and these collectively reflect the interaction activities of a participant. We hypothesise that new joiners who engage more with the existing community early on are more likely to stay for longer. This is based on the observation that after removing nearly 83% of accounts (posting two or less number of emails), the remaining 17% of the accounts formulate over 90% of the total volume of emails in the archives. Thus, the extent to which a new joiner interacts with the active community can influence their ability/motivation to remain engaged. Since Early leavers get inactive within 1 year of joining IETF, we consider analysing interaction behaviour of participants of all the three categories (above) in the first year of their participantship.
To understand whether a new joiner interacts more with young participants (other new joiners) or participants who have been in IETF for a long time we categorise the network nodes as one of the categories identified in the GMM model:
Senior participants: when the age of this participant, at the time of interaction with a new joiner, is 5 or more years.
Mid-age participants: when the age of this participant, at the time of interaction with a new joiner, is between 1 and 5 years.
Young participants: when the age of this participant, at the time of interaction with a new joiner, is 1 or less than 1 year.
We, now, have three types of categories for new joiners based on the number of years that they will remain in the IETF., early leavers, mid-level stayers, and long-term stayers. And, we also have three types of categories for their network viz., senior participants, mid-age participants, and young participants. To understand the interaction dynamics we look at two types of interactions:
Outgoing interaction (new joiner responds to an email from the network: email sent)
Incoming interaction (network responds to an email by new joiner: email received)
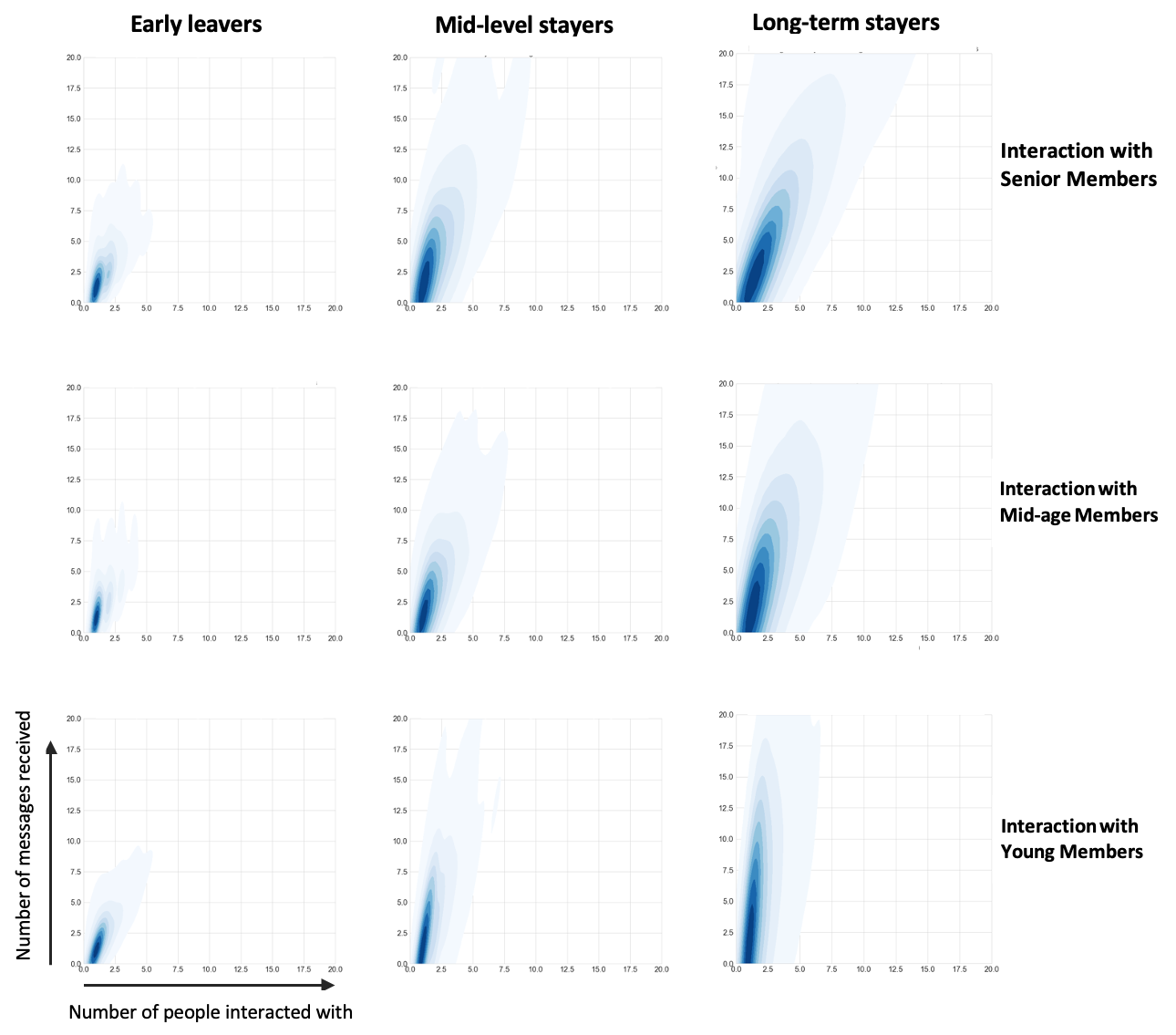
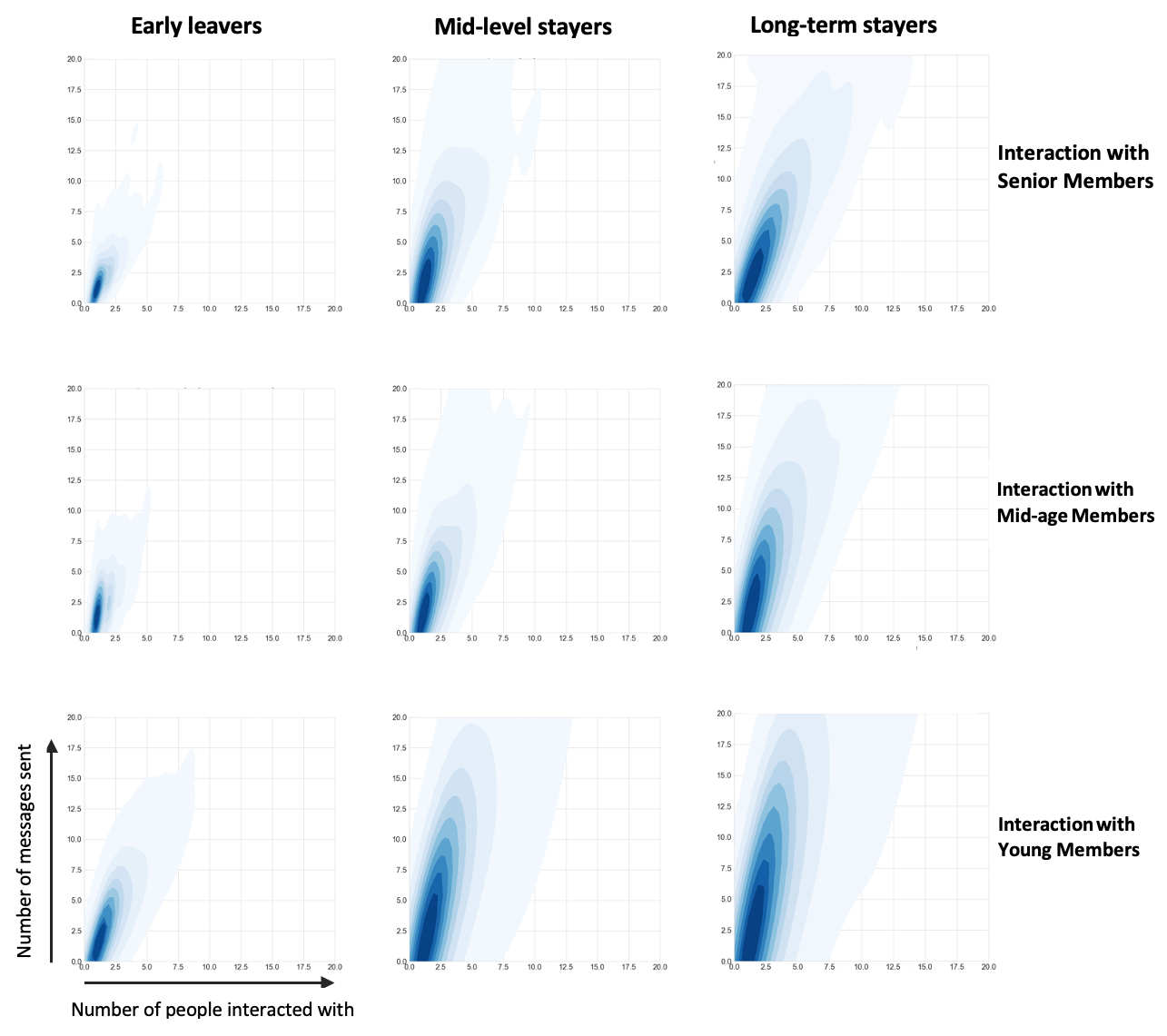
Next, for each new joiner we evaluate how many people (from each network category) they have an outgoing or incoming interaction with, and how many messages were covered in these interactions respectively (in the first year of their IETF lifespan). We do this to observe if the joiners from individual categories reflect any specific behaviour with respect to how they interact with their network, for instance, if the long-term stayers show a certain behavioural aspect, in terms of interactions, which early leavers do not. We record first year interactions for the new joiners in the years 2000-2013. We select the years till 2013 to make sure that there is enough time for participants to acquire whatever age they could go on to acquire till the time data was collected (in 2020), and avoid bias towards younger participants. For e.g. a new joiner, Person A, has outgoing interactions with 10 participants of the mid-age participant category sending 15 messages. We plot graphs, in Figures 3 and 4, showing incoming and outgoing interactions respectively, between new joiners across three categories and their corresponding network. We make the following observations:
Early leavers engage significantly less with the senior participants or mid-age participants. For instance, early leavers send less than 1 email as outgoing interactions, on average, to senior participants. The incoming interactions from senior participants are much lower than the outgoing interactions.
In their first year, long-term stayers not only take initiative to interact with the senior community but are also responded to by the senior participants of the community. Long-term stayers send more than 4 emails as outgoing interactions, on average, to senior participants. The incoming interactions from senior participants are close to 4 on average.
Mid-level stayers interact more with senior participants as compared to the early leavers, and send out over 2 emails as outgoing interactions, on average, to senior participants.
Conclusion
While the longevity of association of a person with the IETF might have more than one influencing factor, it is an important observation that participants who go on to remain associated with the IETF community for a long time, engage more with the senior participants and mid-age participants of the community in their early years. Getting a response back from the community in the mailing lists can turn out to be a motivating factor for a new joining participant. We also aim to explore how these interactions are reflected in the conversations, and how strongly the context of conversations play a role in these interactions and thereby, influencing the longevity of a person's association with IETF.
Additional figures
Incoming interactions, from IETF participants to new joinee (in their first year) of types: Early leavers (max age <= 1 year), Mid-level stayers (max age 1-5 years), and Long-term stayers (max age >= 5 years). IETF participants are classified as senior (age >= 5 at time of interaction with new joinee), mid-age (age 1-5 at time of interaction), and young (age <= 1 at time of interaction) (Figure 3)
Outgoing interactions, from new joinees in their first year of joining depending on the longevity of the new joinee (Early leavers, max age <= 1 year; Mid-level stayers, max age 1-5 years; Long-term stayers,max age >= 5 years), and the seniority (at the time of the interaction) of the IETF participants they interact with (senior participants, age >=5; mid-age, age 1-5; young participants, age <= 1) (Figure 4)